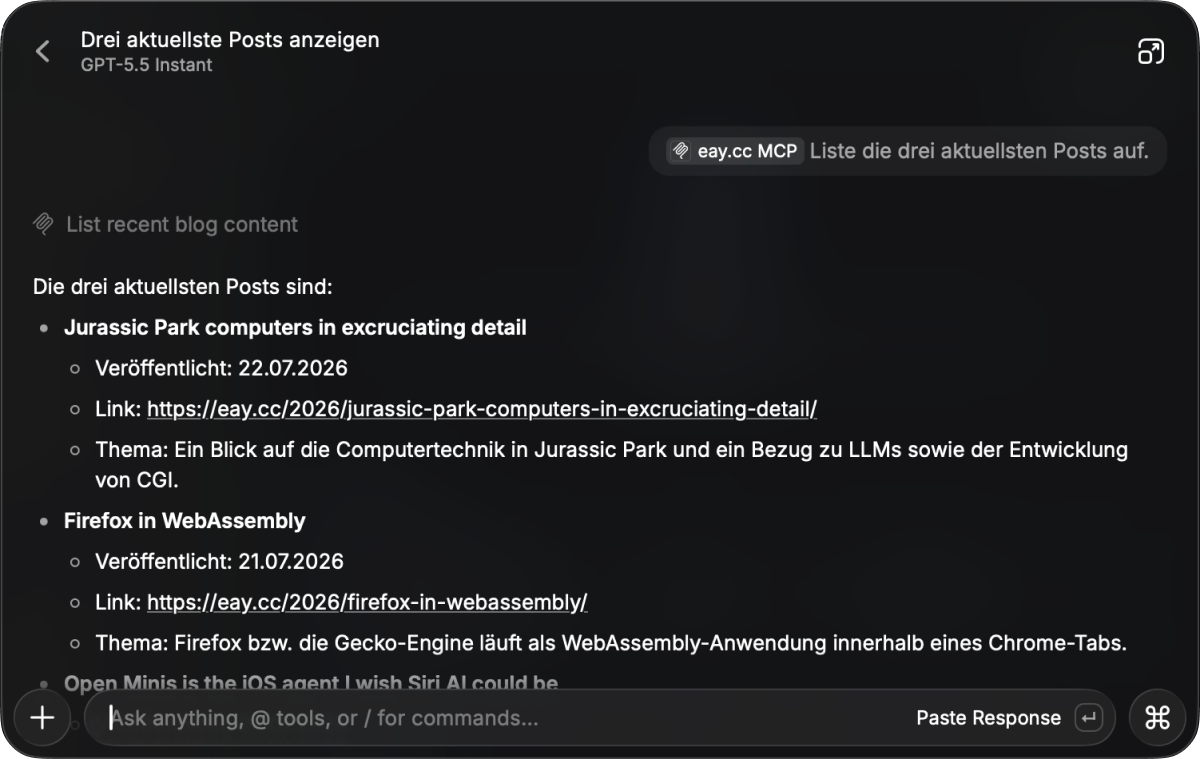
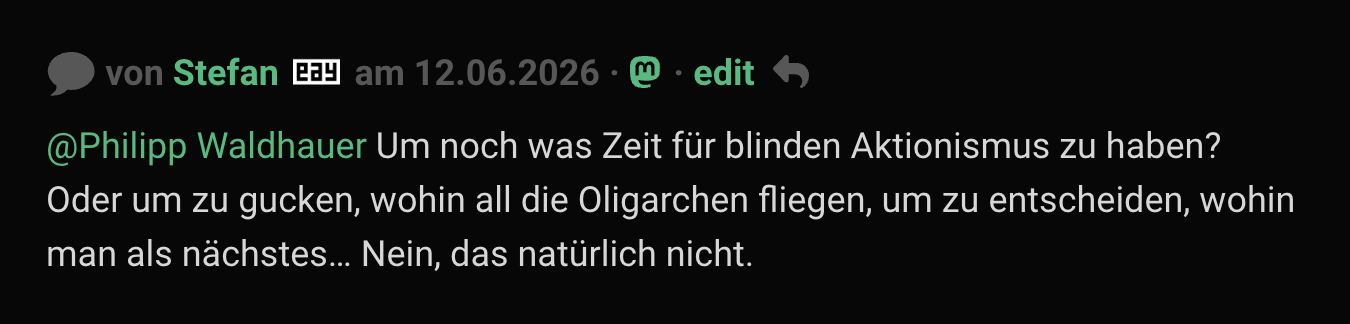
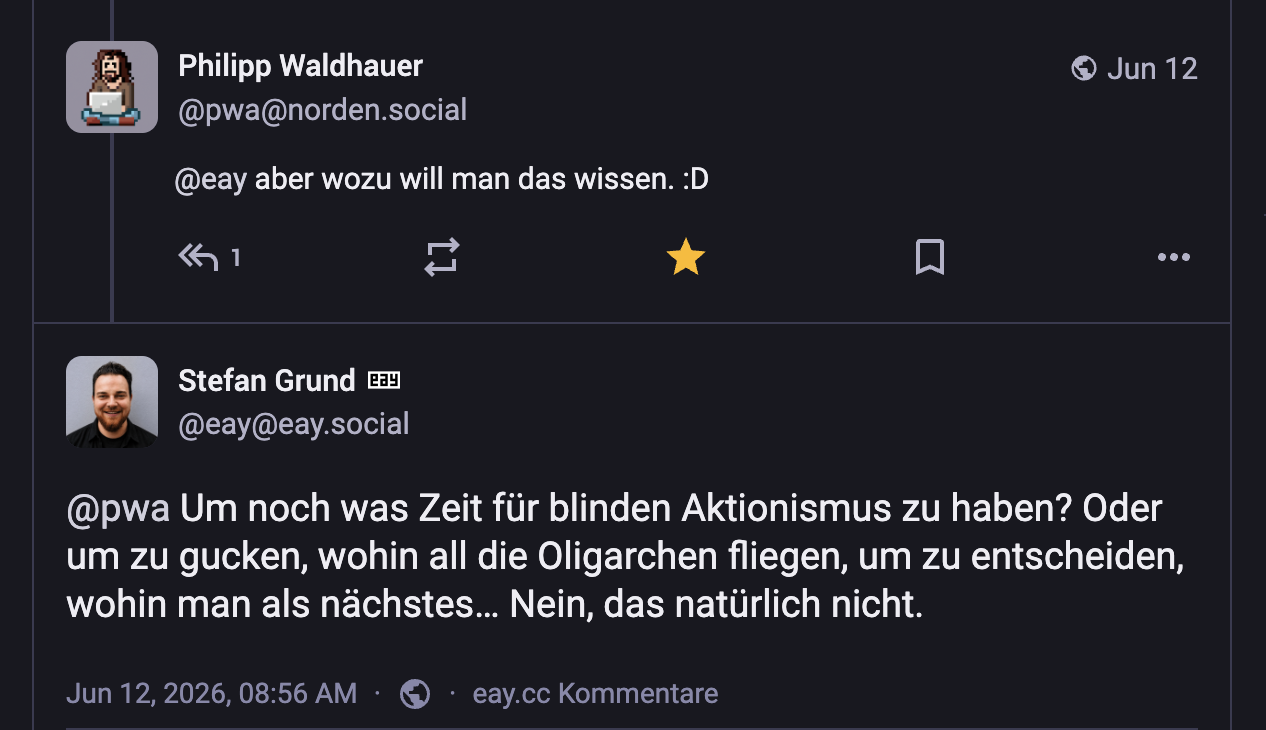
Browse speakers from past FFConf who still publish on their own blog.
FFConf: Speaker Feeds
ffconf.org
FF Conf - Web development & JavaScript conference in Brighton, UK
FF Conf - the UK's best web conference in Brighton.