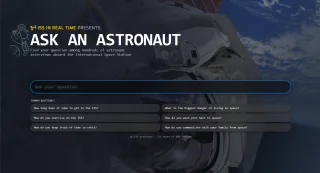
Ask an Astronaut is a searchable archive of real questions asked of NASA astronauts during in-flight interviews, press conferences, and student Q&A sessions aboard the International Space Station, spanning more than two decades of human spaceflight.
Tolles Archiv, das neben dem Transkript jeweils den passenden Videoausschnitt anzeigt, von Ben Feist und David Charney, den Machern von ISS in Real Time und ihresgleichen selbst NASA-Mitarbeiter.